
In this page one can find the results of the OAEI 2014 campaign for the MultiFarm track. The details on this data set can be found at MultiFarm data set. If you notice any kind of error (wrong numbers, incorrect information on a matching system, etc.) do not hesitate to contact us (for the mail see below in the last paragraph on this page).
For the 2014 campaign, part of the data set has been used for a kind of blind evaluation. This subset include all the pairs of matching tasks involving the edas and ekaw ontologies (resulting in 36x24 matching tasks), which were not used in previous campaigns. We refer to evaluation as edas and ekaw based evaluation in the following. Participants were able to test their systems on the freely available subset of matching tasks (open evaluation) (including reference alignments), available via the SEALS repository, which is composed of 36x25 tasks.
We distinguish two types of matching tasks : (i) those tasks where two different ontologies have been translated into different languages; and (ii) those tasks where the same ontology has been translated into different languages. For the tasks of type (ii), good results are not directly related to the use of specific techniques for dealing with ontologies in different natural languages, but on the ability to exploit the fact that both ontologies have an identical structure.
This year, only 3 systems use specific cross-lingual methods: AML, LogMap and XMap. All of them integrate a translation module in their implementations. LogMap uses Google Translator API and pre-compiles a local dictionary in order to avoid multiple accesses to the Google server within the matching process. AML and XMap use Microsoft Translator, and AML adopts the same strategy of LogMap computing a local dictionary. The translation step is performed before the matching step itself.
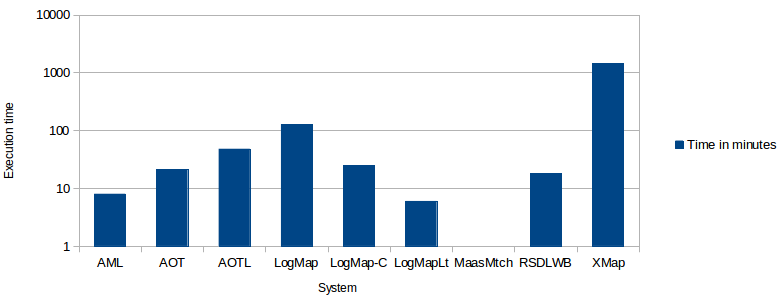
For both settings, the systems have been executed on a Debian Linux VM configured with four processors and 20GB of RAM running under a Dell PowerEdge T610 with 2*Intel Xeon Quad Core 2.26GHz E5607 processors, under Linux ProxMox 2 (Debian). All measurements are based on a single run. Some exceptions were observed for MaasMtch, and it was not able to be executed under the same setting than the other systems. Thus, we do not report on execution time for this system.
The table below present the aggregated results for the open subset of MultiFarm, for the test cases of type (i) and (ii). These results have been computed using the Alignment API 4.6. We did not distinguish empty and erroneous alignments. We observe significant differences between the results obtained for each type of matching task, in terms of precision, for all systems, with lower differences in terms of recall. As we could expect, all systems implementing specific cross-lingual techniques generate the best results for test cases of type (i). A similar behavior has also been observed for the tests cases of type (ii), even if the specific strategies could have less impact due to the fact that the identical structure of the ontologies could also be exploited instead by the other systems. For cases of type (i), while LogMap has the best precision (in detriment of recall), AML has similar results both in terms of precision and recall and outperforms the other systems in terms of F-measure (for both cases). The reader can refer to the OAEI paper for a more detailed discussion on these results.
| Different ontologies (i) | Same ontologies (ii) | |||||||||||||||||
| System | Size | Precision | F-measure | Recall | Size | Precision | F-measure | Recall | ||||||||||
| Specific cross-lingual matchers | AML | 11.40 | .57 | .54 | .53 | 54.89 | .95 | .62 | .48 | |||||||||
| LogMap | 5.04 | .80 | .40 | .28 | 36.07 | .94 | .41 | .27 | ||||||||||
| XMap | 110.79 | .31 | .35 | .43 | 67.75 | .76 | .50 | .40 | ||||||||||
| Non-specific matchers | AOT | 106.29 | .02 | .04 | .17 | 109.79 | .11 | .12 | .12 | |||||||||
| AOTL | 1.86 | .10 | .03 | .02 | 2.65 | .27 | .02 | .01 | ||||||||||
| LogMap-C | 1.30 | .15 | .04 | .02 | 3.52 | .31 | .02 | .01 | ||||||||||
| LogMapLt | 1.73 | .13 | .04 | .02 | 3.65 | .25 | .02 | .01 | ||||||||||
| MaasMtch | 3.16 | .27 | .15 | .10 | 7.71 | .52 | .10 | .06 | ||||||||||
| RSDLWB | 1.31 | .16 | .04 | .02 | 2.41 | .34 | .02 | .01 | ||||||||||
| AML | AOT | AOTL | LogMap | LogMapC | LogMapLt | MaasMtch | RSDLWB | XMap | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | F-m. | Size | F-m. | Size | F-m. | Size | F-m. | Size | F-m. | Size | F-m. | Size | F-m. | Size | F-m. | Size | F-m. | |
| cn-cz | 7.25 | .45 | 106.30 | .01 | 1.30 | .00 | 2.05 | .24 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 14.05 | .29 |
| cn-de | 8.35 | .49 | 106.30 | .01 | 1.30 | .00 | 1.35 | .17 | 1.00 | .00 | 1.40 | .00 | 1.05 | .00 | 1.00 | .00 | 14.65 | .28 |
| cn-en | 9.95 | .55 | 106.30 | .00 | 1.30 | .00 | 1.85 | .23 | 1.00 | .00 | 1.40 | .00 | 1.10 | .00 | 1.00 | .00 | 15.50 | .26 |
| cn-es | 1.05 | .54 | 106.30 | .00 | 1.30 | .00 | 1.85 | .20 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 13.60 | .30 |
| cn-fr | 9.65 | .49 | 106.30 | .01 | 1.30 | .00 | 2.05 | .19 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 86.10 | .01 |
| cn-nl | 6.20 | .38 | 106.30 | .01 | 1.30 | .00 | 1.40 | .18 | 1.00 | .00 | 1.40 | .00 | 1.10 | .00 | 1.00 | .00 | 15.25 | .25 |
| cn-pt | 9.65 | .51 | 106.30 | .01 | 1.30 | .00 | 1.75 | .23 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 12.80 | .25 |
| cn-ru | 3.60 | .40 | 106.30 | .01 | 1.30 | .00 | 2.50 | .27 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 3145.15 | .01 |
| cz-de | 11.25 | .53 | 106.25 | .04 | 1.45 | .02 | 5.75 | .46 | 1.60 | .06 | 2.15 | .09 | 4.00 | .26 | 1.75 | .09 | 15.90 | .41 |
| cz-en | 13.15 | .63 | 106.30 | .05 | 2.00 | .04 | 7.90 | .60 | 1.25 | .04 | 1.70 | .04 | 4.65 | .28 | 1.30 | .04 | 18.70 | .41 |
| cz-es | 13.40 | .61 | 106.30 | .04 | 2.10 | .11 | 7.65 | .47 | 1.50 | .07 | 2.20 | .11 | 3.85 | .25 | 1.80 | .11 | 16.70 | .50 |
| cz-fr | 13.00 | .55 | 106.30 | .04 | 1.40 | .01 | 5.05 | .44 | 1.00 | .00 | 1.50 | .01 | 2.90 | .17 | 1.10 | .01 | 16.75 | .47 |
| cz-nl | 12.20 | .60 | 106.30 | .05 | 1.55 | .04 | 7.25 | .52 | 1.15 | .02 | 1.65 | .04 | 4.65 | .27 | 1.25 | .04 | 14.40 | .02 |
| cz-pt | 13.25 | .59 | 106.30 | .04 | 1.90 | .08 | 6.95 | .51 | 1.60 | .09 | 2.35 | .13 | 3.20 | .22 | 1.95 | .13 | 16.05 | .46 |
| cz-ru | 1.70 | .63 | 106.30 | .01 | 1.30 | .00 | 5.65 | .47 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 17.25 | .41 |
| de-en | 12.85 | .56 | 106.30 | .06 | 4.35 | .19 | 6.75 | .56 | 2.50 | .20 | 2.90 | .20 | 7.15 | .37 | 2.50 | .20 | 17.00 | .40 |
| de-es | 12.70 | .52 | 106.25 | .05 | 1.40 | .00 | 5.50 | .43 | 1.85 | .09 | 1.80 | .06 | 3.90 | .28 | 1.40 | .06 | 13.45 | .43 |
| de-fr | 13.35 | .51 | 106.30 | .04 | 1.65 | .04 | 3.75 | .34 | 1.15 | .02 | 1.65 | .04 | 4.05 | .24 | 1.25 | .04 | 14.45 | .41 |
| de-nl | 1.25 | .49 | 106.30 | .06 | 1.90 | .04 | 5.15 | .44 | 1.25 | .03 | 1.75 | .04 | 5.05 | .25 | 1.35 | .04 | 14.90 | .33 |
| de-pt | 12.00 | .50 | 106.30 | .03 | 1.70 | .04 | 4.95 | .44 | 1.40 | .06 | 1.90 | .07 | 2.65 | .17 | 1.50 | .07 | 13.45 | .39 |
| de-ru | 8.55 | .48 | 106.25 | .01 | 1.30 | .00 | 3.40 | .32 | 1.00 | .00 | 1.40 | .00 | 1.05 | .00 | 1.00 | .00 | 16.30 | .36 |
| en-es | 13.60 | .59 | 106.30 | .07 | 2.70 | .04 | 8.50 | .61 | 1.70 | .10 | 1.70 | .04 | 5.85 | .33 | 1.30 | .04 | 15.75 | .46 |
| en-fr | 13.75 | .54 | 106.30 | .06 | 4.40 | .10 | 5.60 | .50 | 1.55 | .06 | 1.80 | .04 | 6.65 | .33 | 1.25 | .04 | 17.30 | .42 |
| en-nl | 12.30 | .57 | 106.25 | .07 | 3.95 | .07 | 7.10 | .53 | 1.65 | .05 | 2.30 | .10 | 6.35 | .33 | 1.60 | .07 | 18.25 | .38 |
| en-pt | 13.20 | .58 | 106.30 | .07 | 2.60 | .05 | 7.30 | .56 | 1.40 | .06 | 1.85 | .06 | 3.85 | .23 | 1.40 | .06 | 16.45 | .44 |
| en-ru | 11.20 | .60 | 106.30 | .01 | 1.30 | .00 | 4.65 | .37 | 1.00 | .00 | 1.40 | .00 | 1.30 | .00 | 1.00 | .00 | 21.30 | .38 |
| es-fr | 14.55 | .57 | 106.30 | .09 | 1.60 | .01 | 5.95 | .45 | 1.40 | .06 | 1.50 | .01 | 4.85 | .30 | 1.10 | .01 | 93.85 | .02 |
| es-nl | 13.35 | .59 | 106.30 | .05 | 1.40 | .00 | 7.15 | .41 | 1.00 | .00 | 1.40 | .00 | 4.45 | .20 | 1.00 | .00 | 16.40 | .45 |
| es-pt | 13.45 | .57 | 106.30 | .10 | 3.40 | .18 | 8.20 | .51 | 3.00 | .20 | 3.95 | .23 | 9.35 | .36 | 3.55 | .23 | 18.35 | .43 |
| es-ru | 12.05 | .55 | 106.30 | .00 | 1.30 | .00 | 6.55 | .43 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 17.30 | .43 |
| fr-nl | 12.60 | .55 | 106.30 | .06 | 3.15 | .12 | 4.45 | .40 | 1.90 | .11 | 2.40 | .12 | 4.65 | .29 | 2.00 | .13 | 17.70 | .42 |
| fr-pt | 14.05 | .55 | 106.30 | .06 | 1.50 | .00 | 5.35 | .48 | 1.00 | .00 | 1.40 | .00 | 3.15 | .16 | 1.00 | .00 | 17.55 | .43 |
| fr-ru | 11.50 | .53 | 106.30 | .00 | 1.30 | .00 | 3.95 | .36 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 17.25 | .39 |
| nl-pt | 12.65 | .57 | 106.30 | .04 | 1.55 | .01 | 6.00 | .46 | 1.10 | .01 | 1.50 | .01 | 3.00 | .07 | 1.10 | .01 | 16.25 | .42 |
| nl-ru | 9.90 | .52 | 106.30 | .01 | 1.30 | .00 | 4.95 | .38 | 1.00 | .00 | 1.40 | .00 | 1.10 | .00 | 1.00 | .00 | 19.40 | .41 |
| pt-ru | 11.00 | .52 | 106.30 | .00 | 1.30 | .00 | 5.25 | .41 | 1.00 | .00 | 1.40 | .00 | 1.00 | .00 | 1.00 | .00 | 16.95 | .40 |
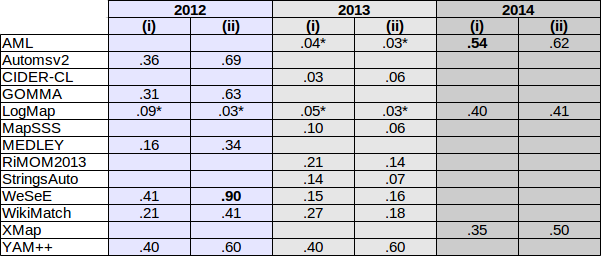
Table below presents a comparison, in terms of F-measure, of the systems implementing some cross-lingual strategy in at least one OAEI campaign. For the results marked with one *, the corresponding system version has not implemented specific strategies for the corresponding year. Best F-measures for cases (i) and (ii) over the years are indicated in bold face.
You can download the complete set of generated alignments. These alignments have been generated by executing the tools with the help of the SEALS infrastructure. All results presented above were based on these alignments. You can download as well additional tables of results (including precision and recall for each pair of languages), for both types of matching task (i) and (ii).
This year we have included edas and ekaw in a (pseudo) blind setting. In fact, this subset was, two years ago, by error, available on the MultiFarm web page. Since that, we have removed it from there and it is not available as well for the participants via the SEALS repositories. However, we can not guarantee that the participants have not used this data set for their tests.
We evaluate this subset on the systems implementing specific cross-lingual strategies. The tools run in the SEALS platform using locally stored ontologies. Table below presents the results for AML and LogMap. Using this setting, XMap has launched exceptions for most pairs and its results are not reported for this subset. These internal exceptions were due to the fact that the system exceeded the limit of accesses to the translator. While AML includes in its local dictionaries the automatic translations for the two ontologies, it is not the case for LogMap (real blind case). This can explain the similar results obtained by AML in both settings. However, LogMap has encountered many problems for accessing Google translation server from our server, what explain the decrease in its results and the increase in runtime (besides the fact that this data set is slightly bigger than the open data set in terms of ontology elements). Overall, for cases of type (i) -- remarking the particular case of AML -- the systems maintained their performance with respect to the open setting.
| Different ontologies (i) | Same ontologies (ii) | ||||||||
| System | Time | Size | Precision | F-measure | Recall | Size | Precision | F-measure | Recall |
| AML | 14 | 12.82 | .55 | .47 | .42 | 64.59 | .94 | .62 | .46 |
| LogMap | 219 | 5.21 | .77 | .33 | .22 | 71.13 | .19 | .14 | .11 |
| XMap | - | - | - | - | - | - | - | - | - |