In this page, we report the results of the OAEI 2021 campaign for the MultiFarm track. The details on this data set can be found at the MultiFarm web page.
If you notice any kind of error (wrong numbers, incorrect information on a matching system, etc.) do not hesitate to contact us (for the mail see below in the last paragraph on this page).
We have conducted an evaluation based on the blind data set. This data set includes the matching tasks involving the edas and ekaw ontologies (resulting in 55 x 24 tasks). Participants were able to test their systems on the open subset of tasks, available via the SEALS repository. The open subset counts on 45 x 25 tasks and it does not include Italian translations.
We distinguish two types of matching tasks :
As we could observe in previous evaluations, for the tasks of type (ii) which is similar ontologies, good results are not directly related to the use of specific techniques for dealing with cross-lingual ontologies, but on the ability to exploit the fact that both ontologies have an identical structure. This year, we report the results on different ontologies (i).
This year, 6 systems have registered to participate in the MultiFarm track: ALOD2Vec, AML, ATMatcher, LogMap, LogMapLt and Wiktionary. This numbers remains stable with respect to the last campaing (6 in 2020, 5 in 2019, 6 in 2018, 8 in 2017, 7 in 2016, 5 in 2015, 3 in 2014, 7 in 2013, and 7 in 2012). This year, we lost the participation of Lily and VeeAlign, but we received new participation from ALOD2Vec and ATMatcher. The reader can refer to the OAEI papers for a detailed description of the strategies adopted by each system.
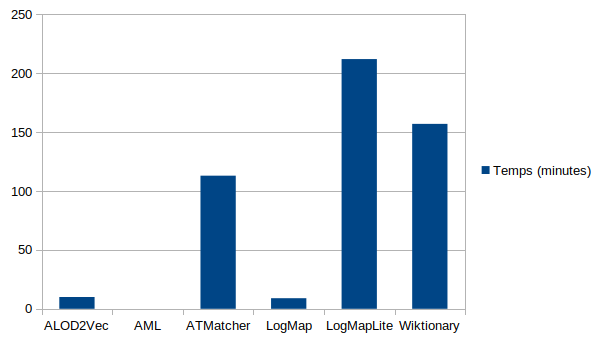
The systems have been executed on a Ubuntu Linux machine configured with 32GB of RAM running under a Intel Core CPU 2.00GHz x8 processors. All measurements are based on a single run. As for each campaign, we observed large differences in the time required for a system to complete the 55 x 24 matching tasks: ALOD2vec (10 minutes), AML (time not produced), ATMatcher (113), LogMap (9 minutes), LogMapLt (212 minutes) and Wiktionary (157 minutes). These number are not comparable to those from last year given the fact that this year MELT framework was used instead of SEALS framework. These measurements are only indicative of the time the systems require for finishing the task in a common environment.
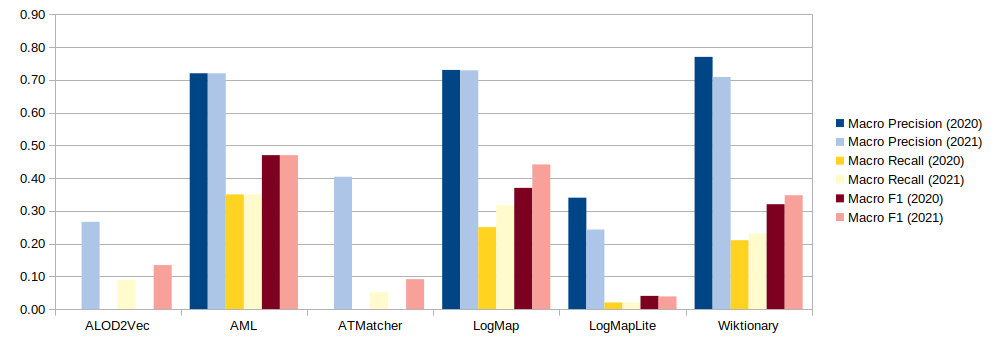
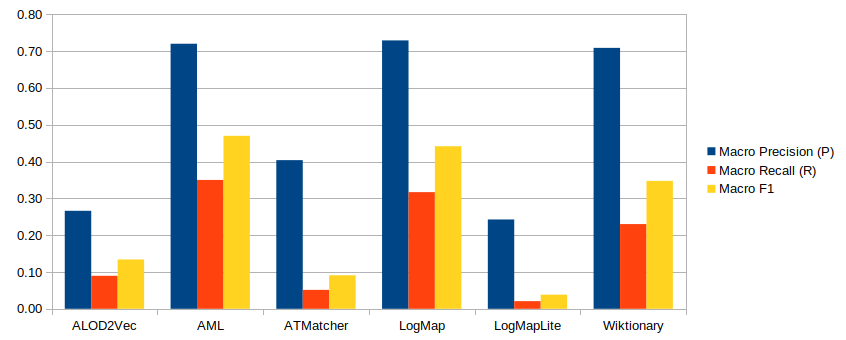
The table below presents the aggregated results for the matching tasks. MultiFarm aggregated results per matcher for different ontologies. Time is measured in minutes (for completing the 55x24 matching tasks), ** runtime is not reported.
| Different ontologies (i) | |||||
|---|---|---|---|---|---|
| System | Time(Min) | Prec. | F-m. | Rec. | |
| ALOD2Vec | 10 | .27 | .13 | .09 | |
| AML | ** | .72 | .47 | .35 | |
| ATMatcher | 113 | .40 | .09 | .05 | |
| LogMap | 9 | .73 | .44 | .32 | |
| LogMapLt | 212 | .24 | .04 | .02 | |
| Wiktionary | 157 | .71 | .35 | .23 | |
AML, LogMap, LogMapLt and Wiktionary have participated last year. Unfortunately, we lost VeeAlign participation this year but we compensate it with two new tools (ALOD2Vec and ATMatcher). Comparing the results from last year, in terms F-measure (cases of type i), AML maintains its overall performance (.47 in 2020, .45 in 2019, .46 in 2018, .46 in 2017, .45 in 2016 and .47 in 2015). On the other hand, LogMap has slightly increased its F-measure (.37 in 2020, .37 in 2019, .37 in 2018, .36 in 2017, and .37 in 2016). The performance in terms of f-measure of Wiktionary slightly increases f-measure to 0.35 (.32 in 2020, .31 in 2019).
Table below presents the results per pair of language, involving matching different ontologies (test cases of type i).