
Web page content
This year, there were 7 participants (Agent-OM, ALIN, LogMap, LogMapLt, LSMatch, Matcha, and MDMapper) that managed to generate meaningful output. These are the matchers that were submitted with the ability to run the Conference Track. Agent-OM is new matcher participating in this year.
You can download a subset of all alignments for which there is a reference alignment. We provide the alignments as generated by the MELT platform and in case of OntoMatch, we modified the generated alignments to match the MELT outputs. Alignments are stored as follows: SYSTEM-ontology1-ontology2.rdf.
Tools have been evaluated based on
We have three variants of crisp reference alignments (the confidence values for all matches are 1.0). They contain 21 alignments (test cases), which corresponds to the complete alignment space between 7 ontologies from the OntoFarm data set. This is a subset of all ontologies within this track (16) [4], see OntoFarm data set web page.
Here, we only publish the results based on the main (blind) reference alignment (rar2-M3). This will also be used within the synthesis paper.
For the crisp reference alignment evaluation, you can see more details - we provide three evaluation variants for each reference alignment.
Regarding evaluation based on reference alignment, we first filtered out (from alignments generated using MELT platform) all instance-to-any_entity and owl:Thing-to-any_entity correspondences prior to computing Precision/Recall/F1-measure/F2-measure/F0.5-measure because they are not contained in the reference alignment. In order to compute average Precision and Recall over all those alignments, we used absolute scores (i.e. we computed precision and recall using absolute scores of TP, FP, and FN across all 21 test cases). This corresponds to micro average precision and recall. Therefore, the resulting numbers can slightly differ with those computed by the MELT platform as macro average precision and recall. Then, we computed F1-measure in a standard way. Finally, we found the highest average F1-measure with thresholding (if possible).
In order to provide some context for understanding matchers performance, we included two simple string-based matchers as baselines. StringEquiv (before it was called Baseline1) is a string matcher based on string equality applied on local names of entities which were lowercased before (this baseline was also used within anatomy track 2012), and edna (string editing distance matcher) was adopted from benchmark track (wrt. performance it is very similar to the previously used baseline2).
With regard to two baselines we can group tools according to matcher's position (above best edna baseline, above StringEquiv baseline, below StringEquiv baseline) sorted by F1-measure. Regarding tools position, all tools keep the same position in ra1-M3, ra2-M3 and rar2-M3. There are five matchers above edna baseline (ALIN, LogMap, Matcha, Agent-OM, MDMapper), and two matchers above StringEquiv baseline (LogMapLt and LSMatch). None of the matcher scored below StringEquiv baseline. Since rar2 is not only consistency violation free (as ra2) but also conservativity violation free, we consider the rar2 as main reference alignment for this year. It will also be used within the synthesis paper.
Based on the evaluation variants M1 and M2, two matchers (LSMatch and MDMapper) do not match properties at all. Naturally, this has a negative effect on the overall tools performance within the M3 evaluation variant.
For the crisp reference alignment evaluation, you can see more details - we provide three evaluation variants for each reference alignment.
Table below summarizes performance results of tools that participated in the last 2 years of OAEI Conference track with regard to reference alignment rar2.
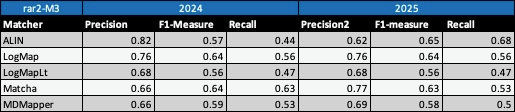
Based on this evaluation, we can see that two of the matching tools (LogMap, LogMapLt) did not change the results. ALIN slightly decreased in precision and increased in recall and F1-measure. Matcha and MDMapper increased in precision, but decreased in recall and F1-measure.

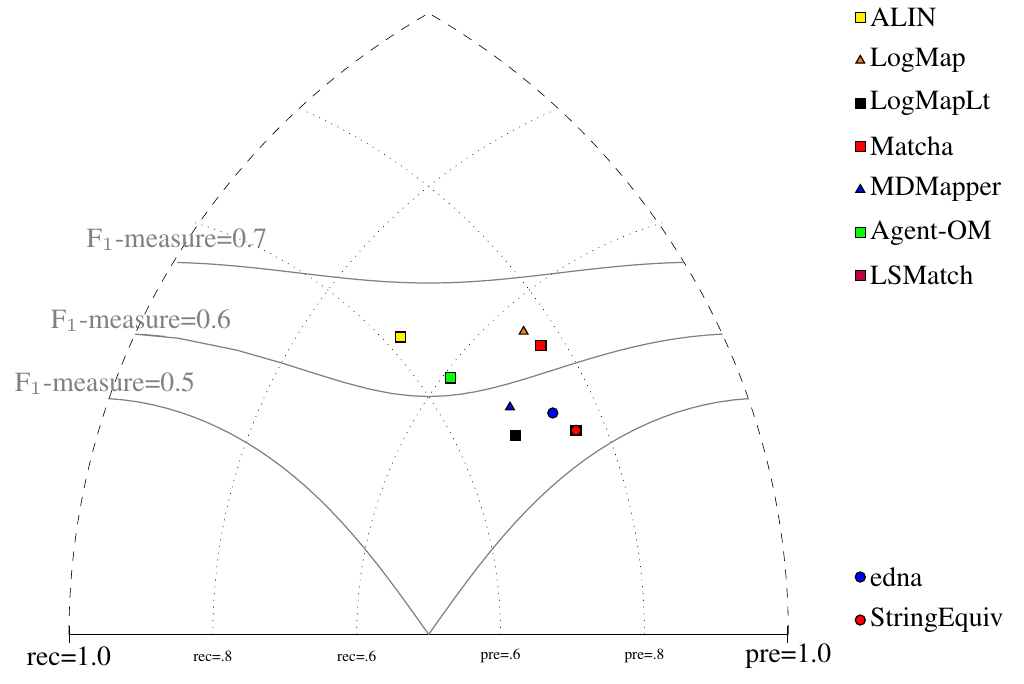
All tools are visualized in terms of their performance regarding an average F1-measure in the figure below. Tools are represented as squares or triangles. Baselines are represented as circles. Horizontal line depicts level of precision/recall while values of average F1-measure are depicted by areas bordered by corresponding lines F1-measure=0.[5|6|7].
The confidence values of all matches in the standard (sharp) reference alignments for the conference track are all 1.0. For the uncertain version of this track, the confidence value of a match has been set equal to the percentage of a group of people who agreed with the match in question (this uncertain version is based on reference alignment labeled ra1). One key thing to note is that the group was only asked to validate matches that were already present in the existing reference alignments - so some matches had their confidence value reduced from 1.0 to a number near 0, but no new matches were added.
There are two ways that we can evaluate alignment systems according to these `uncertain' reference alignments, which we refer to as discrete and continuous. The discrete evaluation considers any match in the reference alignment with a confidence value of 0.5 or greater to be fully correct and those with a confidence less than 0.5 to be fully incorrect. Similarly, an alignment system’s match is considered a `yes' if the confidence value is greater than or equal to the system’s threshold and a `no' otherwise. In essence, this is the same as the `sharp' evaluation approach, except that some matches have been removed because less than half of the crowdsourcing group agreed with them. The continuous evaluation strategy penalizes an alignment system more if it misses a match on which most people agree than if it misses a more controversial match. For example, if A = B with a confidence of 0.85 in the reference alignment and an alignment algorithm gives that match a confidence of 0.40, then that is counted as 0.85 * 0.40 = 0.34 of a true positive and 0.85 – 0.40 = 0.45 of a false negative.
Below is a graph showing the F-measure, precision, and recall of the different alignment systems when evaluated using the sharp (s), discrete uncertain (d), and continuous uncertain (c) metrics, along with a table containing the same information. The results from this year show that more systems are assigning nuanced confidence values to the matches they produce.
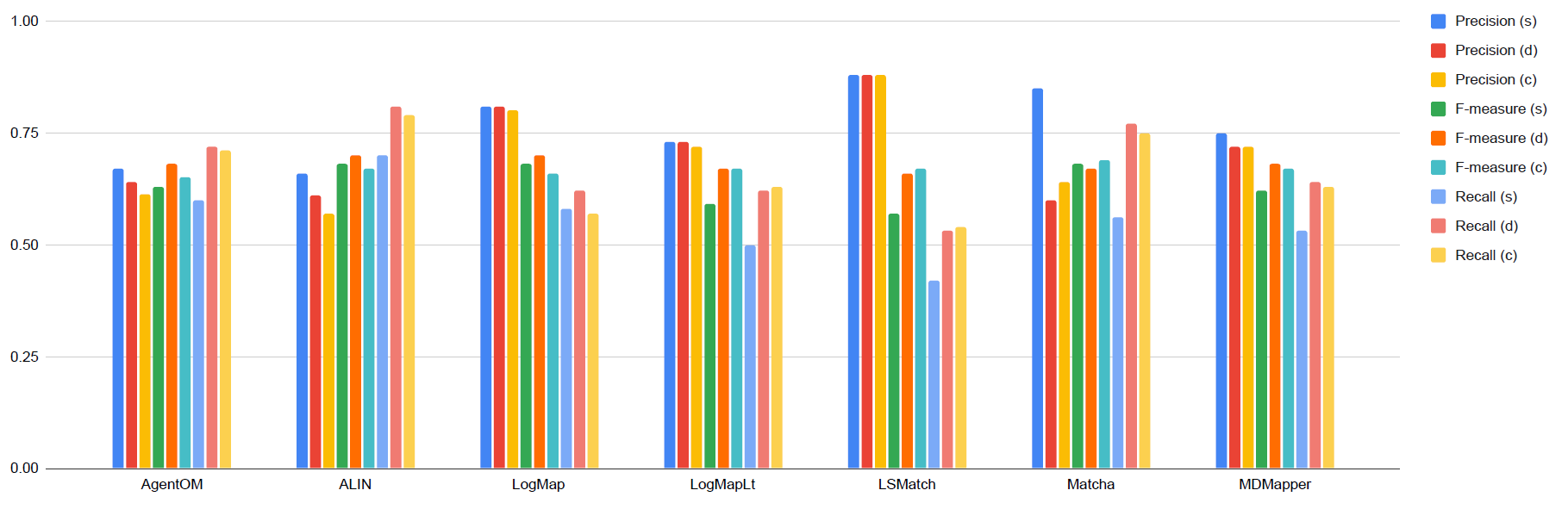
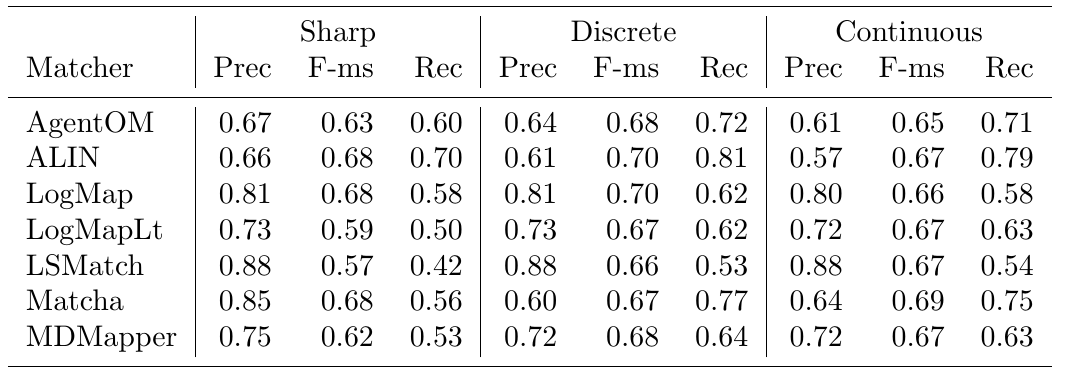
This year, out of the 7 alignment systems, 5 (Agent-OM, ALIN, LogMapLt, LSMatch, MDMapper) use 1.0 as the confidence value for all matches they identify. The remaining 2 systems (LogMap, Matcha) have a wide variation of confidence values.
Compared to 2024, the 2025 results reinforce the usefulness of uncertain reference alignments for distinguishing matcher behavior, while also showing clearer and more consistent recall improvements across systems. Precision remains largely stable across sharp, discrete, and continuous evaluations, but recall and F-measure benefit substantially when uncertainty is introduced. This confirms the trend observed in 2024, while also indicating that system developers are increasingly tuning their outputs to align with consensus-based evaluations.
Systems with fixed confidence assignments (Agent-OM, ALIN, LogMapLt, LSMatch, MDMapper) again show the strongest gains when moving from the sharp to the uncertain evaluations. As in 2024, the discrete metric especially benefits these systems by down-weighting low-consensus matches. ALIN and LogMapLt both demonstrate significant increases in recall and F-measure under the discrete and continuous metrics, confirming their ability to exploit uncertainty even without producing graded confidence values. MDMapper shows a similar pattern, with balanced precision and recall across all evaluation modes.
The two new participants, LSMatch and Agent-OM, follow this same trend. Both assign uniform confidence values but achieve clear improvements when uncertainty is introduced. LSMatch, in particular, achieves the highest precision of all systems (0.88) and translates this into substantial F-measure and recall gains under both discrete and continuous evaluations. Agent-OM, while less precise (0.64–0.67), shows competitive recall and strong performance under the continuous metric, placing it among the more adaptive systems despite its fixed-confidence strategy.
Systems outputting graded confidences (LogMap, Matcha) continue to benefit most from the continuous evaluation, as observed in 2024. Their ability to align internal confidence distributions with consensus-weighted ground truth results in stable precision and higher recall than in the sharp setting. Matcha, in particular, improves substantially in recall under both discrete and continuous evaluations, demonstrating that nuanced confidence assignment is increasingly advantageous as uncertain evaluations become more prominent.
Overall, the 2025 results highlight two main trends relative to 2024. First, recall improvements under uncertain evaluations are broader and more pronounced, reducing the performance gap across systems. Second, the addition of LSMatch and Agent-OM strengthens the observation that even matchers with fixed confidences can achieve competitive results when uncertainty is considered, provided their alignments are consistent with the majority consensus. At the same time, matchers capable of producing meaningful confidence distributions (LogMap, Matcha) remain best positioned to exploit the full potential of continuous evaluation.
For evaluation based on logical reasoning we applied detection of conservativity and consistency principles violations [2, 3]. While consistency principle proposes that correspondences should not lead to unsatisfiable classes in the merged ontology, conservativity principle proposes that correspondences should not introduce new semantic relationships between concepts from one of input ontologies [2].
Table below summarizes statistics per matcher. There are number of alignments (#Incoh.Align.) that cause unsatisfiable TBox after ontologies merge, total number of all conservativity principle violations within all alignments (#TotConser.Viol.) and its average per one alignment (#AvgConser.Viol.), total number of all consistency principle violations (#TotConsist.Viol.) and its average per one alignment (#AvgConsist.Viol.).
Comparing to the last year only three tools (LogMap, and LSMatch) have no consistency principle violation while four tools have some consistency principle violations. Conservativity principle violations are made by all tools. Two tools (LogMap, and LSMatch) have very low number (2, and 21). Further three tools (LogMapLt, Matcha, and MDMapper) have low numbers (less than 100). Agent-OM and ALIN have a bit more than 100 conservativity principle violations. However, we should note that these conservativity principle violations can be "false positives" since the entailment in the aligned ontology can be correct although it was not derivable in the single input ontologies.
Here we list ten most frequent unsatisfiable classes appeared after ontologies merge by any tool.
ekaw#Workshop_Session - 5 ekaw#Session - 5 ekaw#Rejected_Paper - 5 ekaw#Regular_Session - 5 ekaw#Poster_Session - 5 ekaw#Industrial_Session - 5 ekaw#Evaluated_Paper - 5 ekaw#Demo_Session - 5 ekaw#Contributed_Talk - 5 ekaw#Conference_Session - 5
Here we list ten most frequent unsatisfiable classes appeared after ontologies merge by ontology pairs. These unsatisfiable classes were appeared in all ontology pairs for given ontology:
ekaw#Workshop_Session - 4 ekaw#Session - 4 ekaw#Rejected_Paper - 4 ekaw#Regular_Session - 4 ekaw#Poster_Session - 4 ekaw#Industrial_Session - 4 ekaw#Evaluated_Paper - 4 ekaw#Demo_Session - 4 ekaw#Contributed_Talk - 4 ekaw#Conference_Session - 4
Here we list top 10 conservativity principle violations by any tool:
iasted#Session_chair, http://iasted#Speaker - 6 iasted-sigkdd ekaw-iasted iasted#Record_of_attendance, http://iasted#City - 5 edas-iasted ekaw#Presenter, http://ekaw#Paper_Author - 5 edas-ekaw ekaw#Invited_Speaker, http://ekaw#Paper_Author - 5 edas-ekaw conference#Invited_speaker, http://conference#Conference_participant - 5 conference-ekaw iasted#Sponzorship, http://iasted#Registration_fee - 4 iasted-sigkdd iasted#Sponzorship, http://iasted#Fee - 4 iasted-sigkdd iasted#Session_chair, http://iasted#Reviewer - 4 ekaw-iasted iasted#PowerPoint_presentation, http://iasted#Item - 4 conference-iasted edas-iasted iasted#PowerPoint_presentation, http://iasted#Document - 4 conference-iasted edas-iasted
[1] Michelle Cheatham, Pascal Hitzler: Conference v2.0: An Uncertain Version of the OAEI Conference Benchmark. International Semantic Web Conference (2) 2014: 33-48.
[2] Alessandro Solimando, Ernesto Jiménez-Ruiz, Giovanna Guerrini: Detecting and Correcting Conservativity Principle Violations in Ontology-to-Ontology Mappings. International Semantic Web Conference (2) 2014: 1-16.
[3] Alessandro Solimando, Ernesto Jiménez-Ruiz, Giovanna Guerrini: A Multi-strategy Approach for Detecting and Correcting Conservativity Principle Violations in Ontology Alignments. OWL: Experiences and Directions Workshop 2014 (OWLED 2014). 13-24.
[4] Ondřej Zamazal, Vojtěch Svátek. The Ten-Year OntoFarm and its Fertilization within the Onto-Sphere. Web Semantics: Science, Services and Agents on the World Wide Web, 43, 46-53. 2018.