
Matching systems (matchers) have been evaluated based on reference alignment with regard to their precision, recall, F1-measure performance. Brief report about runtimes is also provided. In comparison with the OAEI 2011 conference track, we applied filtering of all correspondences where the most general concept Thing or some individual is employed. None of these alignments are in reference alignment. In theory, this should increase results for matchers.
You can download all alignments delivered by participants. They are in two directories conference11.5 (there are modified OAEI 2011 matchers and new ones) and conference11 (rest of OAEI 2011 matchers) named as it follows: matcher-ontology1-ontology2.rdf.
Reference alignment contains 21 alignments (testcases), which corresponds to the complete alignment space between 7 ontologies from the data set. This is a subset of all ontologies within this track (16). Total number of testcases is hence 120. There are two variants of reference alignment:
In the table below, there are results of all twelve participants with regard to the reference alignment (ra2). There are precision, recall, F1-measure, F2-measure and F0.5-measure computed for the threshold that provides the highest average F1-measure. F1-measure is the harmonic mean of precision and recall. F2-measure (for beta=2) weights recall higher than precision and F0.5-measure (for beta=0.5) weights precision higher than recall.
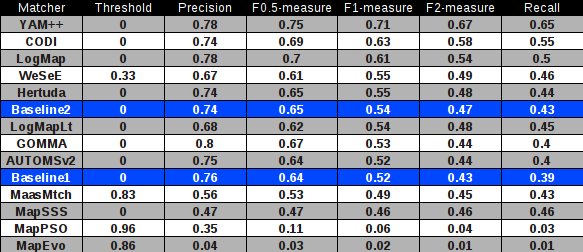
Matchers are ordered according to their highest average F1-measure. Additionally, there are two simple string matchers as baselines. Baseline1 is a string matcher based on string equality applied on local names of entities which were lowercased before. Baseline2 enhanced baseline1 with three string operations: removing of dashes, underscore and 'has' words from all local names. These two baselines divide matchers into four groups:
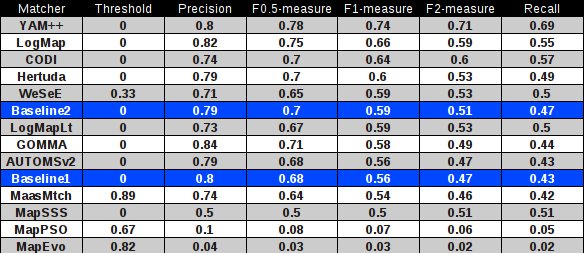
For better comparison with previous year there is also table summarizing performance based on original reference alignment (ra1). In the case of evaluation based on ra1 the results are almost in all cases better by 0.03 to 0.04 points. The order of matchers according to F1-measure is preserved except for CODI and LogMap.
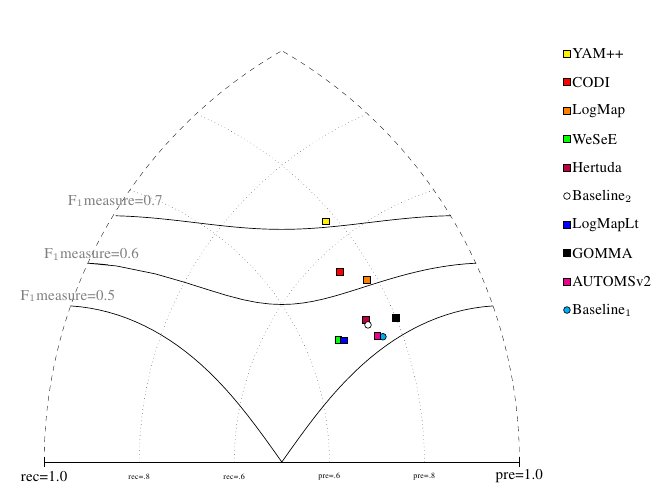
Performance of matchers regarding an average F1-measure is visualized in the figure below where matchers of participants from first two groups are represented as squares. Baselines are represented as circles. Horizontal line depicts level of precision/recall while values of average F1-measure are depicted by areas bordered by corresponding lines F1-measure=0.[5|6|7].
In comparison with the OAEI 2011 results (evaluation based on ra1, see the second table). There are seven modified matchers. Comparison of their results is in the table below:
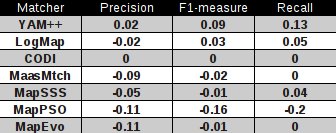
Two matchers increased their results (YAM++ and LogMap). CODI has the same results as for the OAEI 2011. Other four matchers decreased their results.
Finally, we can combine all results (wrt. reference alignment ra2) into one table, see below.
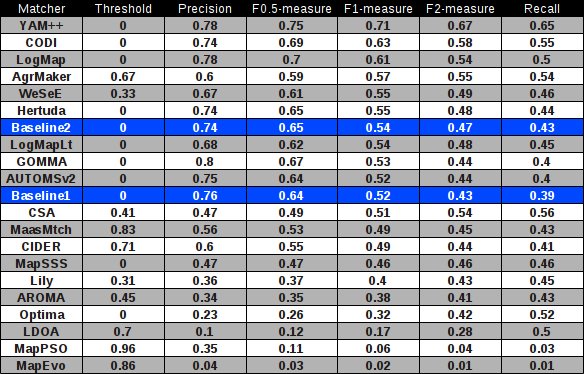
Taking into account the same categorization criterion then we could find the following four groups of matchers:
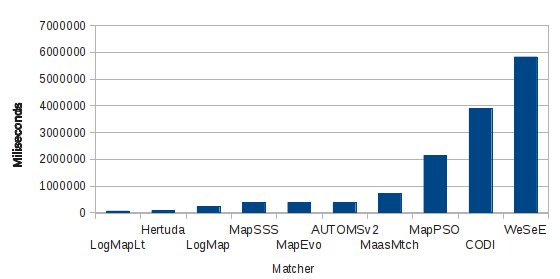
In the plot below, there are total runtimes for ten matchers from OAEI2011.5. Two matchers (YAM++ and GOMMA) could not process all 120 testcases because some ontologies from the whole collection have some syntax problems.
The fastest matchers are LogMapLt and Hertuda which need approximately 1 minute to match all 120 testcases. LogMapLt is a light-weight variant of original LogMap matcher. Next five matchers (LogMap, MapSSS, MapEvo, AUTOMSv2, MaasMtch) need approximately 10 minutes. The slowest matchers (MapPSO, CODI and WeSeE) need half an hour, one hour and one hour and half respectively.
Contact address is Ondřej Šváb-Zamazal (ondrej.zamazal at vse dot cz).