Rules when participating to an evaluation
Until 2011, OAEI participation rules were usually defined within the individual OAEI calls.
Some of these rules were obsoleted by the use of the SEALS platform, but new problems appeared.
So we recall these rules and to clarify them here since they seem to be difficult to understand.
The goal of OAEI is to forster the advancement of ontology matching technology.
So, it aims at evaluating ontology matchers, not "OAEI ontology" matchers.
This means that any effort made to look good at OAEI, as opposed to, improve a matcher, is obviously not in the spirit of OAEI.
The basic rules are as follows:
- Participants should use one system over all tracks,
- with one single set of parameters,
- with whichever resources that are not specifically designed to be adapted to the OAEI data sets.
The interpretations of such rules may not be fully clear.
For instance, a matching system may automatically assign different values to its parameters depending on the input characteristics of the matching task.
This may seem to be adapted to OAEI in some cases, especially if the tool design have used OAEI data sets as guidelines.
One way to be less at odds with OAEI organisation, is to make any adaptative behaviour explicit in the system description submitted to the OAEI organisers (see examples below).
Similarly, if a system re-uses another matching systems or some of its core libraries, this has to be made explicit in the system description (this is attribution common sense).
In such a case it is required that the authors clarify exactly in how far the included libraries have been extended and what is the expected impact on the results.
In case they want to clarify compliance, organisers reserve the right to ask relevant questions to participants and, if answers are not satisfactory, to ask them for their source code.
Participant may decide or not to disclose their code; organisers reserve the right to publish results or not.
How to interpret OAEI rules
The rules above entail that, unless explicitely stated the contrary:
- General purpose resources are authorised; OAEI taylored resources are prohibited.
- The program of the matcher should not be tweaked for passing (or even recognising) the tests;
- Using network connections for accessing a general purpose resource (Wikipedia) is authorised; accessing a specific resources made for OAEI is prohibited;
- Using published OAEI tests (with or without reference alignments) for learning should be considered as prohibited;
- The program should not be used for storing data about the OAEI test sets or to rely on users (except for the interactive tracks in which users are simulated by the organisers);
- It is authorised for a system to behave differently depending on the input which is provided as long as it is not to recognise OAEI data sets.
It is not always easy to see whether a certain aspect of a matching system implementation is valid against the rules.
To enable a better understanding, we present a list of typical examples together with short explanations.
Examples breaking the rules
- Machine learning techniques are used on subsets of (or complete) OAEI datasets to find an optimal weighting of different similarity measures.
- Why incorrect: OAEI datasets cover different types of matching tasks, however, this choice is not representative.
Learning with these examples results in an unacceptable overfitting.
In machine learning there has to be a clear distinction between test data and training data.
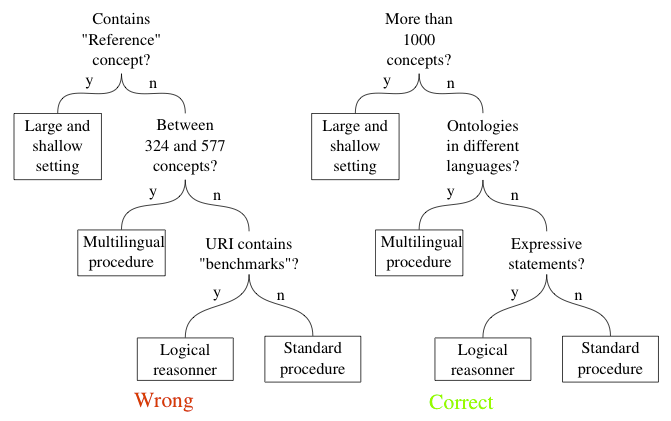
- Several predefined configurations that are activated by detecting certain namespaces, e.g. it is checked for the occurence of a specific string like "benchmark".
- Why incorrect: No need for an explanation.
- A system is trained on OAEI datasets to automatically choose from a set of predefined settings.
- Why incorrect: Such a strategy does not take into account that this approach can result in learning something that works very well for OAEI datasets, but the results of the learning process might nevertheless be completely unreasonable.
Moreover, see the general remark on machine learning from above.
Examples not breaking the rules
- A specific large-scale ontology matching strategy is automatically activated, if the ontologies to be matched have more than 1000 concepts.
- Why correct: This rule of thumb is intended to work well for both OAEI testcases and other ontology matching problems.
It is in general, a reasonable distinction that is guided by detecting a characteristic of the matching problem, which is relevant for solving it.
- The similarity of the ontologies to be matched is measured prior to the core matching process.
The higher the similarity is, the more weight is put in similarity flooding.
- Why correct: For the same reason as above.
- Labels are analysed in a preprocessing step.
If biomedical terms are detected, UMLS is activated as background knowledge.
- Why correct: Again, the same argument as above holds.
Given a non OAEI matching problem, it can be argued that the conditional usage of UMLS will have no negative effects on matching non-biomedical ontologies and probably a positive effect on matching biomedical ontologies.
This listing is for sure not complete.
Please contact OAEI organisers if you are thinking about an issue that is not clarified by this listing.
Drawing settings
In case of doubt, it may be possible to display, and publish, the conditions under which a matcher has different settings.
Here are two different decision tree drawings showing obviously incorrect and acceptable settings: